Notice lowercase t in the logo, uncommon but neat!
It seems I only get motivated to write when I want to glaze someone.
“If you can be anything, be kind”
— Unknown
Today the recipient of this glaze is tenstorrent. It’s a hardware company which has been living in my mind rent-free for the past two years.
But I am a software person, why do I care about a hardware company ? This is because I am serious about my software.
People who are really serious about software should make their own hardware.
— Alan Kay
There is a small sliver of elite programmers that live right at the cusp of software and hardware. They can do things your javascript developer can’t: make hardware dance. Even the documents meant for them demand respect.

To join their ranks, last year I worked on the rust compiler during gsoc. But that’s for CPU, how do I go even more exotic and understand modern accelerator stack ? This turned out to be lot harder. This is a space of extreme acceleration and innovation is happening as we speak. This means there is no course text book which you can refer. All that exist are either thick reference manuals or sprawling codebases:
Shoutout to tinygrad for being tiny.
Even though I spent considerable time reading and understanding them, they don’t speak to me. I am still confused as to how the hardware and software interacts.
Tenstorrent is a hardware company. As it turns out, hardware and software guys don’t like each other. But in the words of their superstar: Jim Keller
Tenstorrent being hardware guys, we have software people. You build hardware, you have to hire software. It’s like a deal with the devil.
—- Jim Keller
Thank god they made the deal with the devil! Their software is literally all open source on github. Many companies periodically dump source available codebases, with no support, then call it open source. Cough, AMD 🤥 (things are looking good with ROCM). Tenstorrent’s entire software stack is open source top to bottom, seriously! They have docs, tech reports, issues being solved, bounty programs, the whole damn package.
And its not just the software, there are hardware goodies too, related to RISC V.
Paraphrasing Jim Keller, they are happy to sell you anything they do. You can buy their IP and then tweak their software to fit your needs. He explains RISCV will be like linux. Open source is a one way street. No one moved away from linux and same will happen with RISCV in the hardware space. Tenstorrent is happy with the flexibility it offers and contribute back to it.
If you are a software person wanting to learn how it interacts with hardware, you should check out their github page. Quick guide for their repos:
Additionally, you should use deepwiki. I am probably responsible for half of the tenstorrent repos indexed over there 🤣. Try this method for understanding their codebases.
Okay sweet, they have oss software. But why have they been living rent-free in my head for 2 years ?
For that lets first understand how modern AI models work.
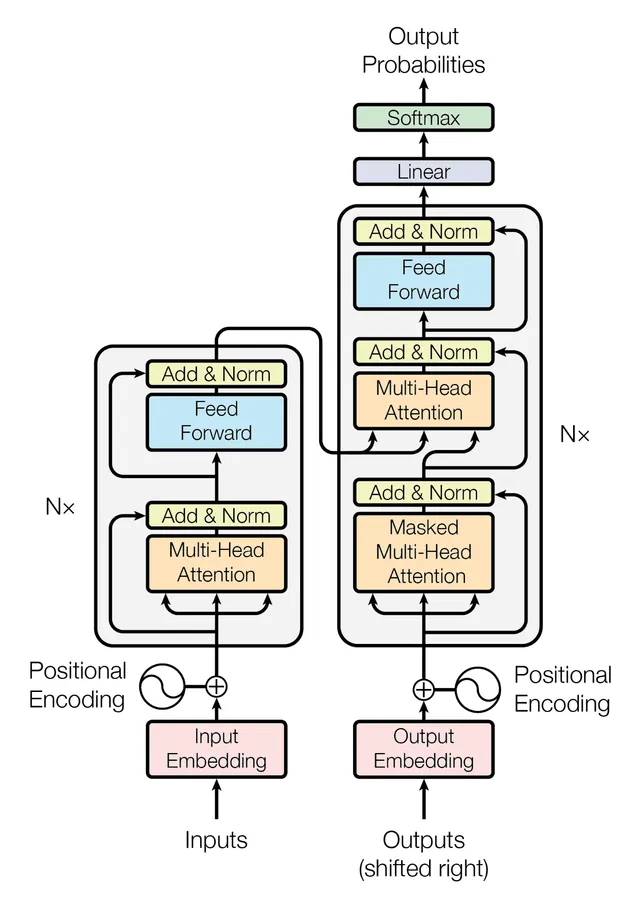
Using a high level framework like pytorch/jax, it can be easily modelled in 100 lines of python. Notice, that the programming model used here is data oriented similar to functional programming languages. Modern large language models do not hold any state between tokens. (There are RNN/LSTM/GRU but we don’t talk about them)
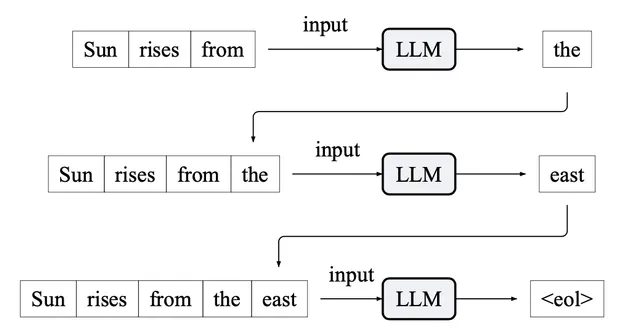
A LLM is trained to predict the next most probably word. Then the output is appended to the original string and the process continues until the end of line special token is received.
A given input moves in a feed forward manner from the starting node to the final node of the model. Thus we can call this connected set of nodes a graph.
tinygrad has 15 UOps. This is a 1024x1024x1024 matmul with a 2x2x2 core, in graph form and in OpenCL form: https://t.co/YNy9NLLAnk pic.twitter.com/SsyaWC7NaZ
— the tiny corp (@tinygrad) October 19, 2023
When an AI compiler compiles a computational graph for a GPU, each graph node typically becomes one or more GPU kernels. A kernel is a piece of code that runs on the GPU. A GPU is made up of several compute cores which can be run in parallel. But crucially all the cores must run the same kernel. So at a time, the entire gpu can only perform one logical task, but in parallel. This works extremely well for graphics when dealing with pixels to render in parallel. But less so for AI model graphs.
In practice GPU have very low Model Flops Utilisation(MFU). Small unoptimised models get around 3-5% MFU (like nanochat). After some optimisations they can get to around 30%. Even at highest level with best minds working on it, we typically max out at 50% MFU. There are several reasons for this:
Many AI ops, especially small matmuls, elementwise ops, and normalization layers are memory-bound. That means GPU spends most cycles waiting for data from High Bandwidth Memory(HBM).
To mitigate this issue, GPU use a SIMT model: Single Instruction, Multiple Threads. Web dev is highly memory bound, where compute is fast, but we have to wait for API responses. Therefore they make heavy use for concurrency, where one thread utilises compute while other waits for response from I/O. Similar idea is used here but at much lower level.
You would be surprised how much time is just data movement.
Here memory related bandwidth is
One analogy I quite like is this.
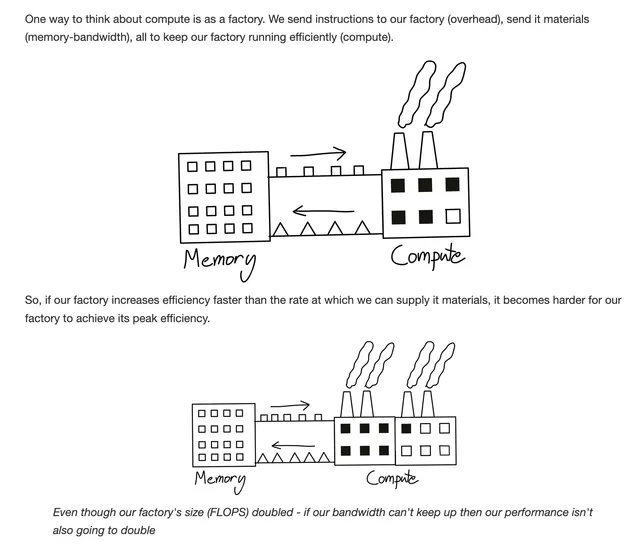
Since the GPU can only run 1 node at a time, for proper GPU utilisation, it is essential that the node has enough parallel tasks to fill the gpu. If the node’s operation doesn’t have enough parallel work to fill the gpu, part of the gpu’s compute cores will sit idle.
During the forward pass, our graph initiates hundreds of separate kernels. Each kernel launch has fixed overhead during which the GPU is stalled.
Checkout MegaKernel by Hazy Research and how they tackle this issue.
Due to feed-forward dependencies, kernels run sequentially. Even if a kernel is small, they can’t be run all at once due to data dependencies.
This can be mitigated to so some extend if you are rich. Each node in the graph takes the entire gpu during which it can not do anything else. But what if we have multiple GPUs. Now we can run independent nodes in pipeline parallesim on individual gpus.
I was not able to verify (probably because it was on zhihu in chinese), but I remember reading that MoE experts in deepseek v3 were designed to maximise this.
If you want a deep dive into their hardware, read:
You know something is exotic when the best source material is a bunch of blogs and github markdown files!
Tenstorrent hardware has Network-on-Chip (NoC) interface. Each compute core called Tensix can communicate to every other core on the chip. In addition the chip has onboard ethernet, which allows several chips to be connected together for massive scaleout. Theoretically, the network can scale to infinity and beyond, while keeping consistent bandwidth. Compilers see an “infinite stream of processing cores.” They don’t need to hand off models to the network or do any shenanigans. The programming model is designed to scale.
Individual compute core is significantly beefed up compared to GPU core. Each core includes a router, packet manager, and a large amount of SRAM. It follows the actor model, where each individual component can be run asynchronously. The router and packet manager synchronize and send the computation packets to the mesh interconnect lines on or off-chip via Ethernet.
If this sounds confusing, read the TT-Metal Guide which contains the Architecture overview with diagrams. I did not want to repeat the explanation when its already so good.
We established early on that modern models are just graphs. Well, the NoC interface of a tenstorrent chip is designed for graph!
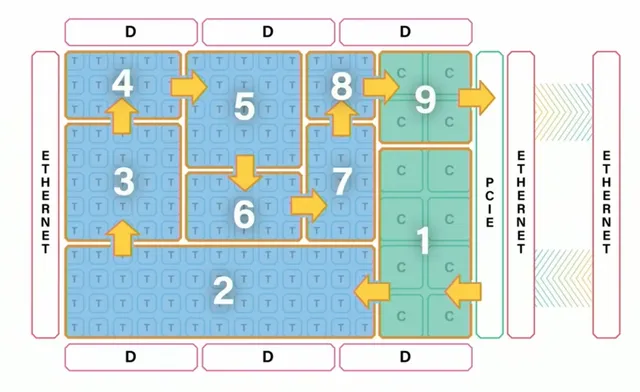
Lets go through each problem we had with the GPU and compare how it is addressed here
Each compute core has 1.5MB SRAM. So model weights can be loaded on the SRAM. Only the actual input data has to move between the NoC between nodes, allowing us to cleanly map the data oriented graph on hardware. No HBM back and forth required.
Each tensix core can run individual kernel and utilises the actor model. Then, if a node can not utilize the entire hardware, we have flexibility to use it for other nodes in dependency graph. This is not just limited to single chip. Even after attaching multiple chips together using ethernet, our logical programming model is still a huge NoC. Thus for bigger model, we still just map the graph on to the cores, just on bigger scale, while our logic remains same. This is huge because a programmer can offload all this to the compiler.
That’s the hardware but there is more! Shiny objects help gain attention, but stories are what keep us coming back. For me, its the Moore’s Law. We have been told Moore’s Law is dead. Transistors are reaching size of atom, we literally can’t scale any further, fair point. But thing really stuck me, when I heard this:
We are reaching physical limits of a single core and so we need multicore processing.
— David Rumelhart
It is from a youtube video with 200 views: David Rumelhart - Brainstyle Computation and Learning. Guess the year?? For me, when I first heard them, I would have believed if someone told me that this was said anywhere in past 5-10 years. But he said this in 1987!!
The truth of the matter is that Moore’s Law in its purest sense has been dead for quite a while. Read this blog from Adi Fuchs: AI Accelerators — Part II: Transistors and Pizza (or: Why Do We Need Accelerators)?.
Neither is it a law. I would argue that it is a target and it is through effort of engineers that we keep matching it. The blog by Adi, explains various different scaling axis we have used and next innovation when one starts to fail. According to The Relentless Pursuit of Moore’s Law, Apple’s M2 chip is right on line of the moore’s law. When I asked Kimi K2 about this, it pointed out that the metric used to measure this has been changed from CPU core(original Moore’s Law) to System-on-Chip. I believe this is just another axis we are scaling on.
This brings me to perhaps my favourite slide by Jim Keller.
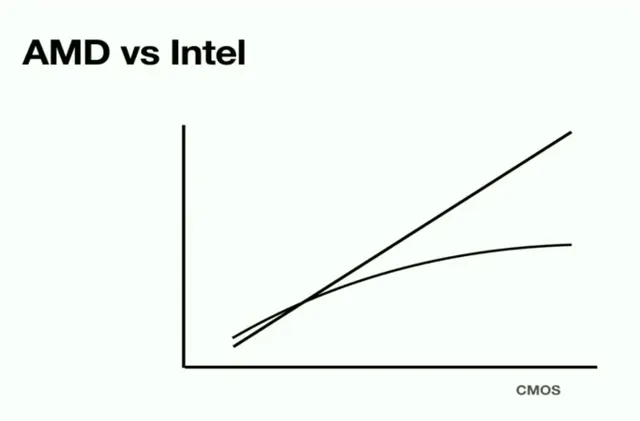
He says:
For example so I was at Apple and two companies AMD and Intel made processors and they came in. I won’t tell you which one was which but one of them said we think computer performance is plateauing for a bunch of reasons- predictability of branches, memory latency, pipeline and a whole bunch of reasons and the other company said we think they’re going to get 10% percent faster every year and they both executed on their plans.
— Jim Keller
I think we can infer which line belongs to whom on the graph.
The players have changed. Jensen Huang has said that Moore’s Law is now dead. Tenstorrent claims 10% percent yearly upgrade.
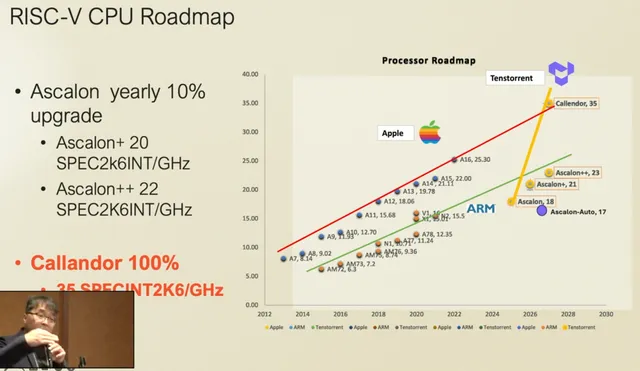
Who is going to execute on their plans ?
I don’t own a tenstorrent card. Like most, I have a MacBook and a dream. I believe at this point, it is generally understood that macbooks are the most common dev device. So it is essential that tenstorrent provide first class dev experience. Currently for my research project, I have a repo on which I iterate locally. When I have to run it on the cloud, all I do is
git clone ... && cd ...
uv sync
uv run main.pyuv and the jax compiler takes care of the rest.
Even apple understand this dev cycle and implementing this in MLX.
We don’t have any plans to drive a Nvidia GPU from a Mac using MLX.
— Awni Hannun (@awnihannun) October 22, 2025
> Testing quietly and efficiently natively and then flipping the switch on for the RTX 40/50 for scaling up
What you can do today is run the same MLX code on a Mac or an Nvidia GPU which has its own host CPU…
Can you enable this “flipping the switch” for tt boards. Maybe something similar to HIP-CPU. Allow running code locally, just to check for correctness during dev cycles, and then flip the switch to run on cloud. So the goal would be “functional correctness validation” locally, not speed.
Wow, you actually made it to the end of this love letter 😁.
If you ever need a college monkey to tinker on tt-metal-cpu or tt-compiler, consider giving this monkey an internship.