My* LLM Awards 2025

Image Adopted from MKBHD's Smartphone Awards
This year I went all in on AI models, how they work, research papers and using them a lot. The pace of progress is so fast that 2025 felt like the longest year of my life. Stuff that happened at the start of the year feels like 1-2 years ago. Naturally I have a lot of thoughts that I want to share as an award show. These are my personal favourites based on my workflow.
Model of the Year: Minimax M2
Starting off with the most interesting award. Minimax M2 launched in October so it’s new. It might seem silly to be giving “Model of the Year” to a model which was present for only 1/4th of the year. However, this model marked a significant shift in the way I use models. This category also reflects my favourite model of the year. It might be surprising that GPT-5 helped influence this outcome. Let’s unpack this..
Adhering to Instructions
GPT-5 was an important release for me. It was the first model
where I gained confidence to let it run in my repository. The
models before this were adamant on doing whatever they like. For example using npm,
even though the repo uses bun. Or again and again trying to use a certain version of a package.
It’s my way or the highway.
— Every LLM ever!
GPT-5 broke this behaviour. The only issue, GPT-5 series has regressed over time with the current GPT-5.2 being the worst of them all. GPT-5.2 feels almost like a scaled up version of GPT-OSS with a small world model but good on benchmarks.
Minimax M2 caught me by surprise. Just as I lost a good intern in GPT-5, Minimax M2 came to replace it. It is very very good at listening to instructions and following them over long contexts. If I give it specific instructions to repeat specific steps over a range of tasks/data, it handles them well. Sometimes, it does need some nudges, but the incredible part is that it will listen to the nudges.
It’s good enough
I don’t “vibe” code. I want to retain a certain level of control over my code. I don’t like sending wishes to the model and hoping it respects them. I like giving small tasks to the models. This gives me enough authority to confidently own the codebase. For this, I often don’t need the best model. Minimax M2 has shown that a 200B param model is good enough. It is relatively fast while being good at tasks I care about.
Cheap
It’s only $0.2 for input and $1.10 for output. Opus 4.5’s cache
read/write is more than this 😂. This is
at least 10 times less than any other flagship model. Believe me, this model is not
1/10 in intelligence. This marks a significant advance in the race to the bottom for
token pricing.

M2 Lands on the Sweet Spot
Minimax M2 hits the perfect spot. It is fast, cheap, intelligent enough and above all a good intern. While M2 wins on control and cost, this next pick is about convenience.
Daily Driver: ChatGPT
This is the model I reach for without thinking. While OpenAI started as a research company, it is pivoting to a user-focused company. It does not have the best model, nor the best UX, nor the best image gen. But the overall experience is good enough at all the right places. It’s basically the Samsung flagship of LLMs. The app is available on all the platforms, GPT-5 is one of the top models, web search integration, the router works most of the time, plus other features like audio conversations, image gen, etc. In addition, the Codex CLI has improved a lot over the year. It is good value in its current iterations.
Overall, a solid experience.
In the current sea of models, often model capability matters less than the how pleasant it is to interact with. The next pick embodies this spirit.
Best UX: Grok
I know people like to trash on Grok, but it’s gotten better. My favourite part of the model’s experience is its UX. It is by far the best UX of any app. Very solid and full of small quality of life features all around. I would go as far as to say that, except for Grok every other chat experience is subpar. Kimi comes as a close runner up. Kimi’s UI has a lot of soul and character, however the model is slow and UI feels sluggish.
For me, an important part of a good UX is a fast and solid model. Grok-4.1 Fast feels good. I often use it for information search or light research. It can access posts from X which is a massive advantage. X is probably the highest quality information stream on the internet. Their image gen called Imagine is also a great experience. The images are not at the level of Nano Banana, but the generation is faster and does not have a visible watermark. Whenever I open Imagine, I am greeted with beautiful videos which somehow always load without delay. I sometimes just open it to see pretty videos.
I would urge you to give it a try.
Pretty pixels buy my attention, personality keeps the tab open.
Best Writing: Kimi K2
I hate the way most models talk. They are all very wordy with high sycophancy. Among these, Kimi K2 stands out. It is fun to talk with and use for writing. Answers to questions are short and concise. I urge readers to compare responses between Kimi K2 and other models. You would be surprised how many empty and useless words every other model uses compared to K2. Recently it became the default model on T3 Chat. Hopefully this will lead to more people finding and appreciating it. For college students, I have free advice for you. Instead of using GPT, use Kimi for writing assignments or paraphrasing. The difference will be day and night.
I also love the boys and girls at Moonshot, the research lab behind Kimi. Kimi K2 was a top contender for Model of the Year until M2 happened.
Conversations end, curiosity doesn’t, so let’s talk about the feature that turned search into a reflex.
Most Interesting: AI Mode
Does anyone remember that Google launched AI in Google Search ? Most people are only familiar with AI Overview and its shenanigans. However, let me tell you, the AI Mode in Google Search is better and I have set it as my default search engine. You can customise this too.
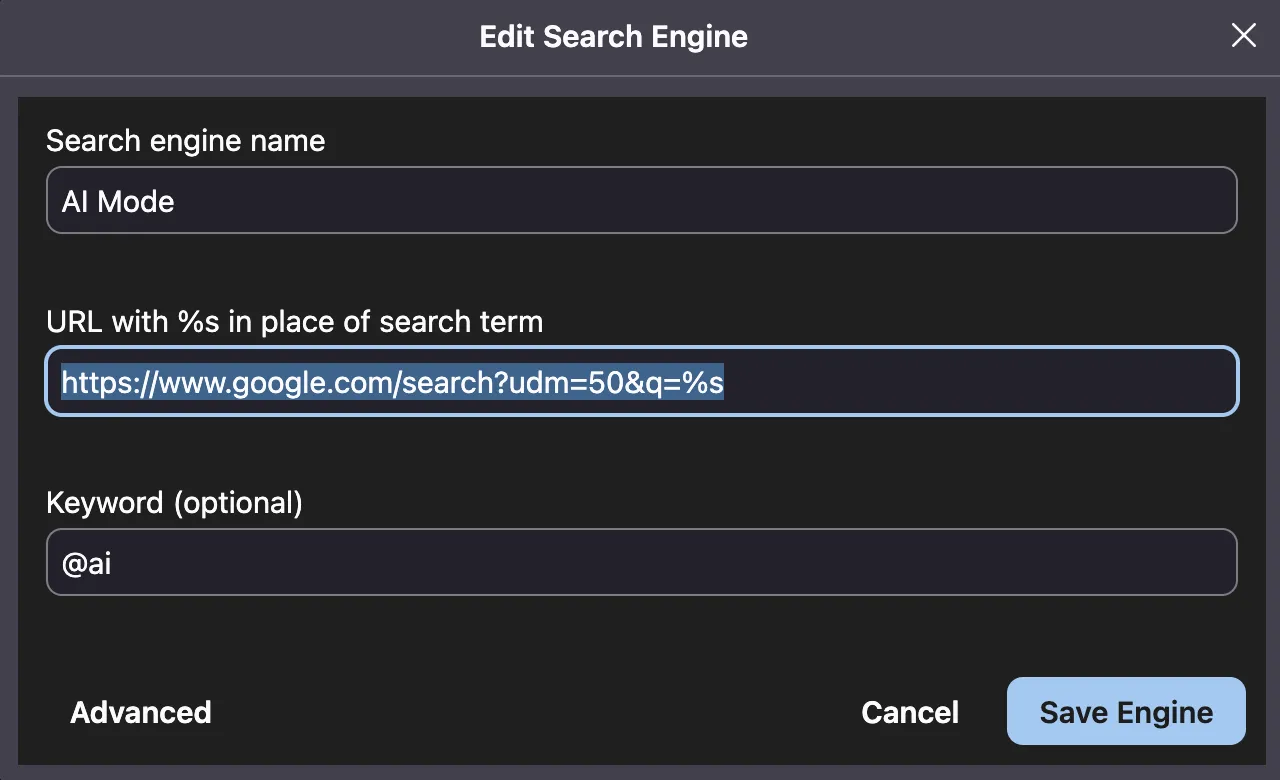
Add AI Mode as search engine
For a long time I was using search.exa.ai as my default search engine. However, then they made some changes and the time to first response increased. I
want my search results to be fast for 95% of the searches. Among these, when I know exactly what I am looking for, I use Google Search. However, when I
am looking for a quick information search(which is most of the time), I use AI Mode. Specifically it
is FAST!! ⚡⚡⚡. All other LLM based search experiences are far slower by comparison.
However, it must be kept in mind for the queries to not be too long or illogical. Because this is likely
a smaller model, if the information is not directly available on the website, it might hallucinate.
For those 5% of the searches where deeper search is required, I use Grok, ChatGPT or Exa depending on phases of the moon.
Speed is great, but a tool that leaves money in your pocket is the one that survives the Monday-morning budget review.
Best Value: Minimax M2

LLM Trilemma
Each model has to choose one of these to focus on. The catch is that each model can be best at at most two of these. Minimax M2 chose Cheap and Fast. But don’t let it fool you, it is also intelligent enough. I have explained this in “Model of the Year” section, but TL;DR: M2 works well as a good intern when guided.
Unfortunately not every flagship justifies its value proposition as well.
Biggest Disappointment: Claude
Oh boy! I know, I know, it’s SOTA on coding with a cult following. But I don’t like it. Remember the Trilemma you saw in the previous section, well Claude is only Intelligent. Otherwise it’s very very expensive $$$ and very very slow. The infra is bad with low rate limits and frequent outages. As you might have gathered, I like fast things and hate to wait if a service is slow.
Everyone loves Claude Code and its open source too. No!. I guess most people don’t read code on Github because the Claude Code repo is just a token repo with no actual code. I do like Claude Code and its a wonderful coding harness. Also nothing wrong with being closed source. I am simply mad about how many people think it is open source. Then there is Claude’s behaviour. I have no better way to describe it other than that it has too many feelings and emotions for a dumb machine. Claude models have notoriously high refusal rates which is a dynamic I don’t enjoy.
Until last year, I was quite excited about Anthropic and Claude but it fell off this year. Claude is still the best model for vibe coding. Hopefully I’ll come around to love it more.
Thankfully, progress this year wasn’t one-sided.
Most Improved: Nano Banana Pro
It’s great to see progress in image gen. I like creative freedom and expression. For the same reason I spent way too much time learning Blender and editing tools. I also love great diagrams and maintain a custom typst template which I use for submitting college assignments. Nano Banana Pro feels like this serene moment when anything can be generated. It has significantly reduced the barrier to entry and time it takes to create an image.
Improved Diagram with Nano Banana Pro
A little effect of this could already be seen in the quality of posters at NeurIPS. I expect the quality of diagrams in papers to go way higher in the coming months.

Remove fence from the front
Does anyone remember the demo at Google I/O 2017 of a fence removed from front of a girl playing baseball ? Well, that was a lie until now. I have been trying to do this for years!! Finally there is a model that can one-shot this!!
Of course, not every model could find a place in my workflow.
Bust of the Year: GLM & Qwen
People often tell me how good GLM and Qwen series are and perform well on benchmarks. However I have never been able to use them for anything productive.
Nvidia’s total cost of operations is so good that even when the competitor’s chips are free it’s not cheap enough.
— Jensen Huang
For example, I would love to use Cerebras for coding. It is insanely faster than anything else. I also love some of the research focused content on their YouTube Channel. On their platform, there was an offer to use 1M tokens daily for free. However they only supported the Qwen and GLM series. I tried to use these models, but they were so bad I could not use them even if they were free.
Even now, GLM 4.7 just came out and it is free on OpenCode. It does feel better than the previous iterations, however does not fit my workflow. This might be a product of how I use LLMs. For example, Gemini models are topping the benchmarks. They seem to be great at one-shotting a very difficult task. But they do not listen to instructions as well. I like models that I can iterate with. Maybe my behaviour will change over time as these models get even better.
The vibes are immaculate with GLM and Qwen. I like those guys. Their models are OSS and I get to learn a lot from them. For the longest time Qwen 2.5 was the go-to model for researchers. However I could never use them in a meaningful manner.
Thank You
And that’s a wrap on LLM Awards 2025! This was subjective, heavily vibes based and benchmark agnostic. If your favorite model didn’t make the stage, blame my terminal, not the leaderboards. The best LLM is still the one that ships your side project at 3 a.m. Here’s to an even weirder, faster and cheaper 2026. Maybe we will meet again in 2026 if robots have not taken over by then.